
Multi-Agent Learning
Cooperative Settings
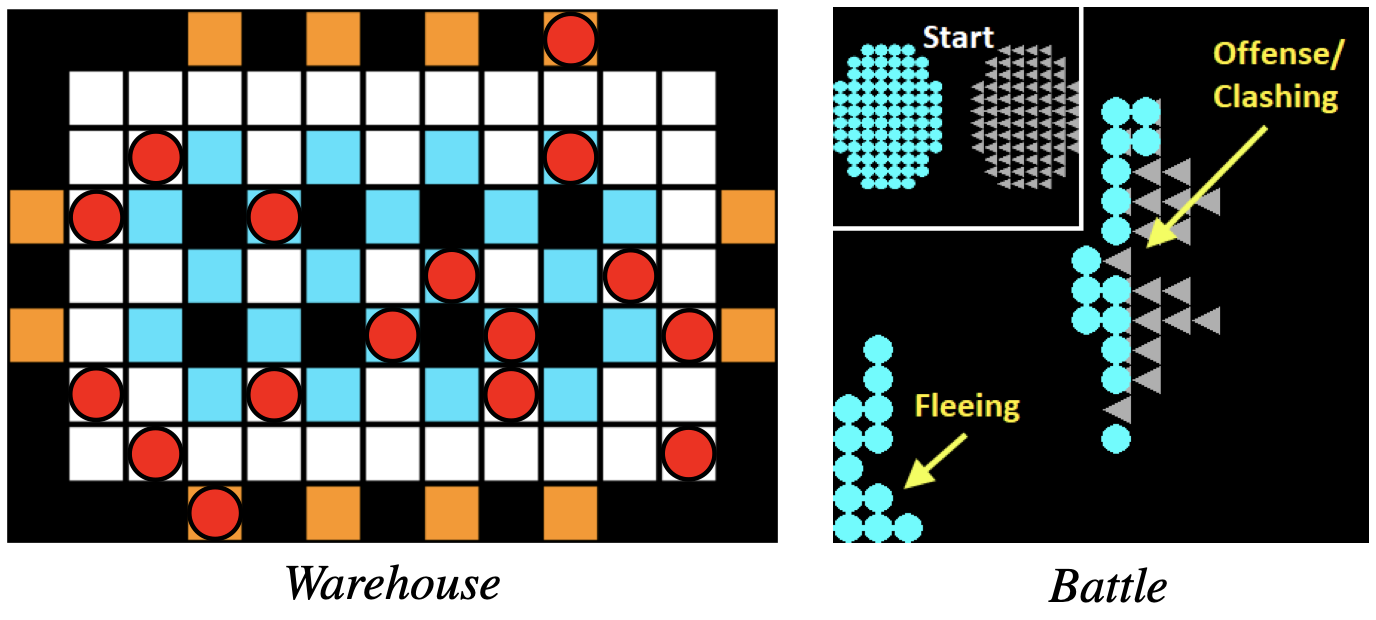
Many real-world problems like fleet management, industry 4.0 scenarios, or communication networks can be formulated as cooperative multi-agent system (MAS), where multiple agents have to collaborate to achieve a common goal. Multi-agent reinforcement learning (MARL) is a promising approach to solve these problems, which has recently achieved remarkable progress in challenging domains like StarCraft II. However, current MARL is still at a preliminary stage, where many real-world aspects are neglected for simplicity therefore limiting practicability.
We address common weaknesses in MARL with respect to the real world beyond classic benchmark optimization like scalability and state uncertainty. Our algorithms are based on value function factorization and use agent hierarchies [1] or attention-based recurrency [2]. In addition, we provide a new benchmark that exhibit higher degrees of state uncertainty through stochastic initial states and noisy observations, which is widely neglected in MARL research [2].
Publications:
[1] Variable Agent Sub-Teams
[2] State Uncertainty
Adversarial Settings

Cooperative MARL agents are commonly trained under idealized condition, assuming that agents will always exhibit cooperative behavior. However, (partial) adversarial behavior may occur nevertheless due to flaws in hardware and software, potentially leading to catastrophic failure. Thus, even cooperative multi-agent system (MAS) need to be prepared for adversarial change as each agent may be a potential source of failure.
We devise adversarial algorithms to improve resilience in MAS. During training, we randomly replace productive agents by antagonists to expose the system to partial adversarial change [1]. We also devise evaluation methods to compare resilience of different MARL algorithms in a fair way [2].
Publications:
[1] Antagonist-Based Learning
[2] Adversarial Value Decomposition
Self-Interested Settings
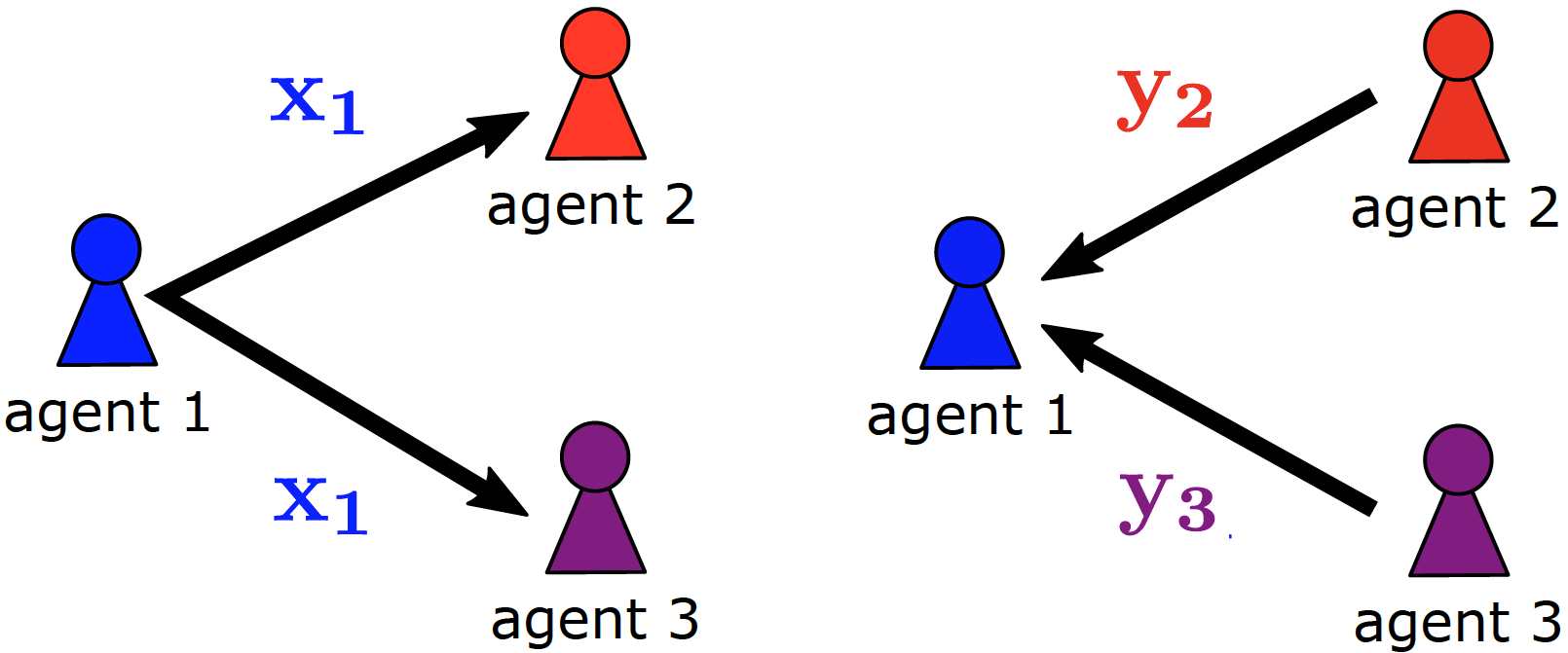
As self-learning agents become more and more omnipresent in the real world, they will inevitably learn to interact with each other. In self-interested MAS, conflict and competition may arise due to opposing goals or shared resources. Naive RL approaches commonly fail to cooperate in such scenarios, leading to undesirable emergent results.
To incentivize cooperative behavior in self-interested MAS, we study decentralized mechanisms, where agents learn to reward or penalize each other. These mechanisms are based on market theory [1] or social behavior like acknowledgments [2,3], which are well studied in other fields. We also consider real-world aspects like defectors, locality of information, and noisy communication [2,3].
Publications:
[1] Action Markets for Emergent Cooperation
[2] Mutual Acknowledgment Exchange for Reciprocity
[3] Reciprocal Peer Incentivization